
近日,由初佃辉教授、涂志莹教授、隋典伯副教授、张柏林副研究员指导,哈尔滨工业大学(威海)计算机科学与技术学院2023级本科生张骞、2022级本科生李昕烨和2024级本科生徐浚豪在自然语言处理领域顶级学术会议ACL 2025 Main Conference(CCF-A类)发表长文《Editing the Moving World: Model Editing for Video LLMs》。
ACL(Annual Meeting of the Association for Computational Linguistics)是自然语言处理与计算语言学领域最具影响力的国际学术会议之一,在全球范围内享有极高学术声誉。ACL长期汇聚该领域最前沿的研究成果,是学术界和工业界公认的重要交流平台。本届ACL 2026共收到12,148篇投稿,其中Main Conference录用率为19%,Findings录用率为18%。
论文首次将模型编辑研究从静态模态拓展至视频大语言模型(Vid-LLMs),提出 VMEB——首个专为 Vid-LLMs 设计的模型编辑评测基准,引入视频专属的「鲁棒性」评测指标,系统揭示现有方法的核心局限,对六种主流编辑方法在四款 Vid-LLMs 上进行全面实验与深度分析。
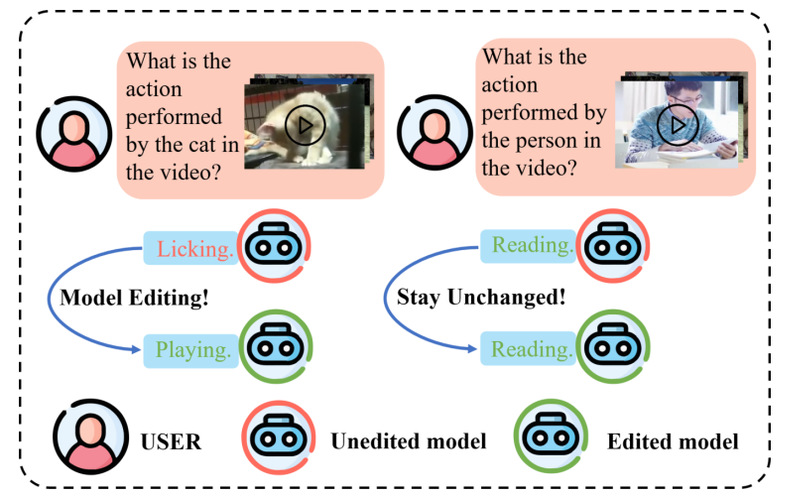
图1 Vid-LLMs 编辑任务概览:红色为编辑前的错误输出,绿色为编辑后的正确输出
传统方法要更新模型,往往需要耗费巨大的计算资源重新训练。模型编辑(Model Editing)技术的目标,精准地修改模型中的特定知识,同时不损坏其他能力——既高效,又可控。这一技术在纯文本领域(如 ROME、MEND、MEMIT)和静态图像领域已有不少研究,但对于视频这种包含时序、运动、空间关系的动态内容,几乎还是一片空白。本研究正是瞄准这一空缺,迈出了第一步。
论文提出了 VMEB(Vid-LLMs Model Editing Benchmark),包含1578 条数据、14个视频子类别,涵盖从目标级理解到情境级推理的四个难度层次,并配套近4000个视频文件。VMEB 的评测维度在传统三大指标基础上有所创新:
• 可靠性(Reliability):编辑后模型能否正确输出目标答案
• 局部性(Locality):编辑是否影响了无关知识(分文本局部性与视频局部性)
• 泛化性(Generality):用改写后的问题提问,模型是否仍能给出正确答案
• 鲁棒性(Robustness):当输入视频经过水平翻转、加速、旋转、灰度化等扰动后,编辑效果是否仍然稳定
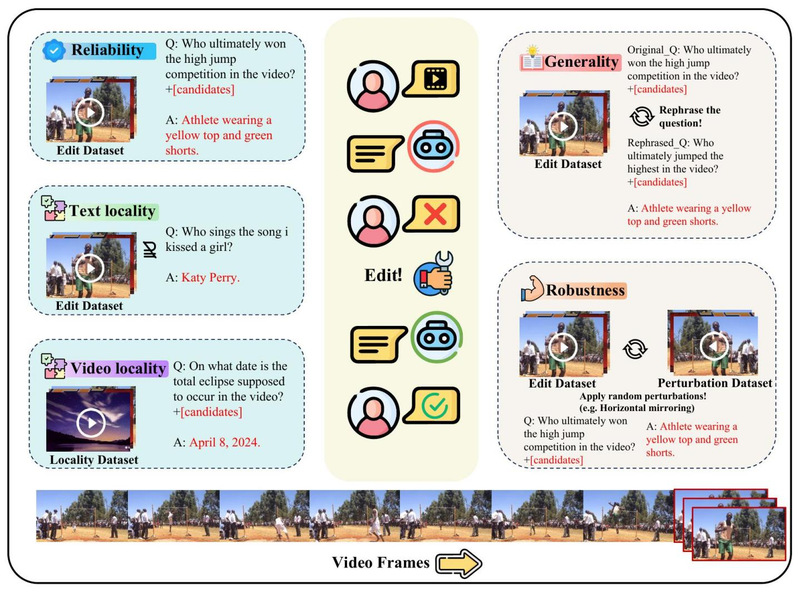
图2 VMEB 评测框架:涵盖可靠性、局部性、泛化性与鲁棒性四大维度
论文在 LLaVA-NeXT-Video(7B)、Qwen2.5-VL(3B/7B)、Qwen3-VL(8B)四款模型上,系统评测了 FT、IKE、MEND、SERAC、AlphaEdit、MEMIT 六种代表性编辑方法,发现综合表现 MEND 最为均衡。FT(微调)虽然可靠性最高(>99%),但会严重破坏视频局部性(<30%),对模型整体能力损伤显著。MEND 在各项指标上表现最为均衡,综合得分最优。AlphaEdit 和 MEMIT 视频局部性极佳(>90%),但可靠性仅约40%,难以真正完成知识注入。
核心发现一:定位困境
AlphaEdit 和 MEMIT 属于定位再编辑(Locate-then-Edit)范式,依赖将知识锁定在某个离散文本 token 上。然而,视频语义是通过交叉注意力机制分散在连续嵌入序列中的,将动态分布式视频信息投影到单一静态 token 在数学上本就是病态问题(ill-posed)。这种结构性不兼容,正是这类方法在 Vid-LLMs 上失效的根本原因,也表明视频原生编辑框架的研究迫在眉睫。
对比编辑视觉层与语言层的差异后发现:语言层蕴含更多隐性知识,与模型最终输出的相关性更强,编辑效率显著优于视觉层。这一结论在所有测试模型和方法上高度一致。
研究团队设计了一个关键实验:将模型的视频输入替换为纯黑帧,测试编辑效果是否下降。结果出人意料——对于 FT 和 IKE 方法,成功率几乎毫无变化。这意味着这些方法根本没有真正理解视觉内容,而是在走文字捷径,仅仅调整了答案分布而非视觉语义理解。MEND 在视频局部性上有显著下降,SERAC 在可靠性上有所降低,说明它们对视觉上下文仍有一定依赖。这一发现深刻揭示了现有方法的本质局限。
这项工作首次系统性地将模型编辑研究拓展至视频大语言模型,提出了覆盖动态视频场景的完整评测体系 VMEB,并通过大量实验揭示了现有方法的核心瓶颈:离散 token 定位范式与连续视频语义之间存在不可调和的结构性矛盾;现有方法大多未能真正实现对视觉内容的理解更新,而是依赖文本层面的快捷路径;多模态模型编辑需要全新的框架设计,而非对纯文本方法的简单移植。未来,该方向有望催生若干重要研究课题:针对连续视频嵌入的原生编辑算法、多帧跨时序的知识一致性保持机制、真实语义扰动下的鲁棒性评测,以及更广泛的多模态知识表示与更新框架。
哈尔滨工业大学(威海) 计算机科学与技术学院(软件学院)
